表观修饰 epigenetic modification
- DNA甲基化
- 组蛋白修饰
- RNA修饰
- 非编码RNA修饰
组蛋白修饰
DNA分子需要高度螺旋折叠为染色质,然后高度螺旋成为染色体,才能放入7μm左右的细胞。该过程需要核小体(nucleosome)的参与。
核小体由H2A、H2B、H3、H4四种组蛋白(Histone)亚基各两个拷贝形成的八聚体和缠绕在外约146bp的DNA组成。
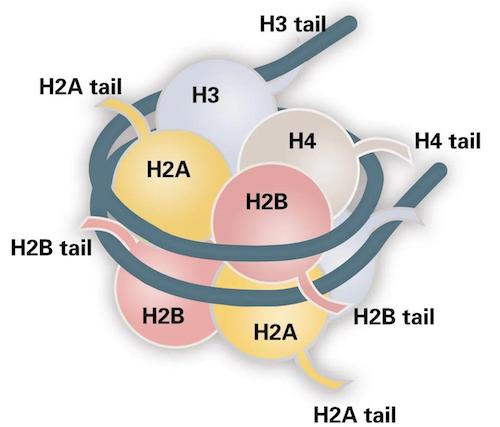
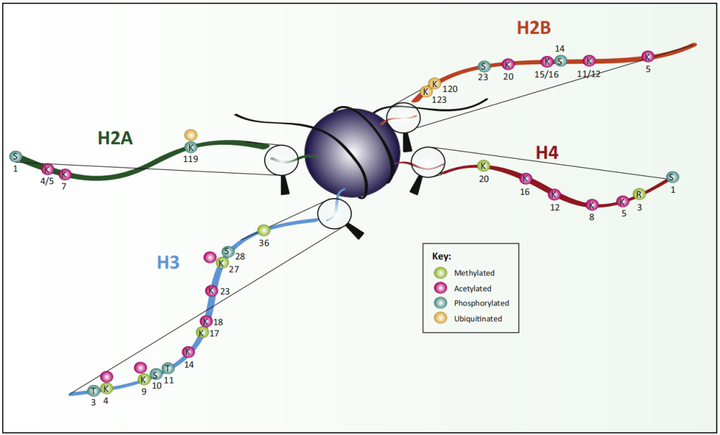
组蛋白在相关酶催化下发生甲基化、乙酰化、磷酸化、泛素化和ADP核糖基化等动态修饰的过程,它可通过招募效应蛋白来改变染色质的开放或凝聚的状态,进而调控基因的表达。
真核生物基因的转录主要分为转录起始(initiation)、暂停-释放(pausing-release)、延伸(elongation)和终止(termination)四个步骤,转录进程的顺利进行与DNA修饰、组蛋白修饰和RNA修饰等表观遗传修饰高度相关。
组蛋白修饰是可逆的共价修饰。共价修饰需要写入(writer)、插除(eraser),读取(reader)等相关的酶来参与。
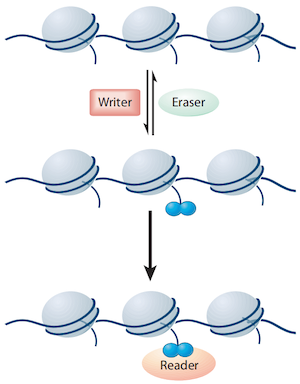
- Writer
是催化化学基团添加到组蛋白上对其进行修饰的酶,例如:乙酰转移酶(HATs)、甲基转移酶(HMTs)、激酶和泛素酶等。
- Eraser
是从组蛋白上去除这些修饰的酶,例如:去乙酰化酶(HDACs)、去甲基化酶(HDMs)、磷酸酶、和去泛素化酶等。
- Reader
是识别特定翻译后修饰的底物并与之特异性结合的蛋白质或蛋白质复合物。
组蛋白修饰描述规则:组蛋白结构+氨基酸名称+氨基酸位置+修饰类型
Promoter (TSS) mark: H3K4m3
Enhancer (TF binding) mark: H3K4me1
Both enhancer and promoter: H3K4me2, H3/H4ac(esp H3K27ac), H2AZ
Repressive mark: H3K27me3(cpG island near promoters)
Long term suppression by DNA methylation: H3K9me3(repeat region in genome)
- H3K4me3
H3K4me3表示组蛋白H3亚基上赖氨酸4的三甲基化。
| Abbr. |
Meaning |
| H3 |
H3 family of histones |
| K |
standard abbreviation for lysine |
| 4 |
position of amino acid residue(counting from N-terminus) |
| me |
methyl group |
| 3 |
number of methyl groups added |
H3K4me2/3在细胞内是通过维持暂停Pol II(paused Pol II)在近端启动子区的稳定而促进基因激活;而H3K4me2/3对转录起始没有明显的调控作用cell reports。
- H3K27me3
H3K27me3表示组蛋白H3亚基上赖氨酸27的三甲基化。
| Abbr. |
Meaning |
| H3 |
H3 family of histones |
| K |
standard abbreviation for lysine |
| 27 |
position of amino acid residue (counting from N-terminus) |
| me |
methyl group |
| 3 |
number of methyl groups added |
- H3K27ac
H3K27ac表示组蛋白H3亚基上赖氨酸27的乙酰化,这种修饰研究的最充分。
| Abbr. |
Meaning |
| H3 |
H3 family of histones |
| K |
standard abbreviation for lysine |
| 27 |
position of amino acid residue (counting from N-terminus) |
| ac |
acetyl group |
H3K27ac主要位于活跃转录基因的启动子和增强子区域,在这些区域它与H3K4me3共存,一起促进基因激活表达(Creyghton et al., 2010)
此外,H3K27ac还可在基因间区域形成超级增强子,进一步促进基因表达(Creyghton et al., 2010) 。
组蛋白乙酰化多发生在组蛋白H3和H4的N端赖氨酸残基上。组蛋白带正电荷,DNA带负电荷,所以组蛋白与DNA结合非常紧密。而组蛋白乙酰转移酶将乙酰辅酶A的>乙酰基转移到组蛋白的赖氨酸残基上,会中和组蛋白的正电荷, 减弱DNA与组蛋白的相互作用,从而使DNA更容易与转录因子结合,因此组蛋白乙酰化往往与转录
激活相关。
两种技术都是通过特异性抗体捕获所要研究的组蛋白修饰,后分离与组蛋白修饰相结合的DNA,并通过对DNA进行测序和分析来推断组蛋白修饰的位置及丰度
- Histone H3K27ac separates active from poised enhancers and predicts developmental state