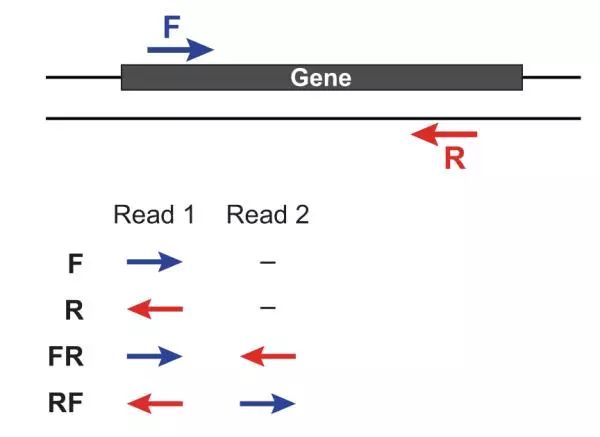
人类血液 blood
人体血液主要有血细胞、血小板和血浆组成。
血细胞 Blood cell 血细胞主要包括红细胞(Red blood cell)、白细胞(White blood cell)。
血浆 Plasma 血浆(plasma)占据总血液(blood)容量的
~55%,是血液中防止凝结的液体部分,更能反映血液在体内的循环情况。 血浆主要是水和溶解在其中的蛋白质、激素、矿物质和二氧化碳。功能:循环液体,保持机体适宜的内环境。血清 Serum 血清和血浆都是血液的重要组成部分,血液由血浆、血清、血小板、白细胞和红细胞组成。血浆和血清的主要区别在于它们的凝血因子不同。
1 | 血浆 = 血清 + 纤维蛋白原 + 凝血因子 |
血小板 Platelet 血小板是血液的一个组成部分,其功能是对血管损伤出血作出反应,形成凝块,从而形成血块。血小板没有细胞核:它们是来自骨髓巨核细胞的细胞质碎片,然后进入循环系统。
人外周血单核细胞 Human Peripheral Blood Mononuclear Cells
人外周血单核细胞(PBMC)是具有单个圆形细胞核的血细胞。这些细胞包括淋巴细胞(T、B和NK细胞)、单核细胞和树突状细胞。pbmc是免疫系统的一部分,对细胞介导和体液免疫至关重要。我们的人pbmc是从正常健康供体白细胞中分离出来的,用酸-柠檬酸-葡萄糖配方A (ACDA)作为抗凝剂收集。所有献血者必须在HBV、HCV和HIV检测中呈阴性,并得到IRB的同意。
血细胞发生(Hematopoiesis)
俗称造血,有造血干细胞完成。造血干细胞(hemopoietic stem cell)是生成各种血细胞的原始细胞,又称为多功能干细胞(multipotential stem cell)。
分离方式
采用离心分离。例如:
1.两次离心: 800Xg + 16,000Xg 用于血浆纯化(Shulin et al., Gut, 2019)。
2.两次离心: 1,600Xg + 13,000Xg, 用于一个队列收集; 2,500rpm (978Xg), 用于另外的队列收集。(Mira et al., Nature, 2022)
胞外RNA(exRNA)
细胞外的RNA(exRNA, extra-celluar RNA)包括长链和短链RNA,主要是来至血浆和血清中的RNA(cf-RNA, cell-free RNA)和富集在外泌体(exosomes)、血浆囊泡(extracellular vesicles)和血清的RNA(exoRNA)。
long RNA (> 200 nt)
mRNA, lncRNA, rRNAsmall nocoding RNA (ncRNA 20-30 nt)
miRNA, piRNA, siRNAother nocoding RNA
tRNA, Y RNA, snRNA, snoRNA, srp RNA等
 *
*